Web服务器可能同时和很多人在通信,服务器需要知道它正在和谁通信,而不是每个客户端都当做一个匿名的用户,这一章主要就是为了讲解服务器如何辨别它正在和谁通信。
###The Personal Touch
HTTP本来就是一种匿名的,无状态,请求响应形式的协议。服务器难以知道在和哪个客户端通信,而且无法跟踪同个用户先后发出的请求。
现代化的浏览器为了给用户提供个性化的体验,它们实现了跟踪用户先后发出的请求的功能。比如亚马逊就为用户提供了以下个性化的功能:每个用户的称呼和网页内容都不同;根据用户的兴趣推荐商品;自动填充用户个人信息,比如地址电话邮箱等等。
这一章我们将总结几种HTTP识别用户的方法。
- 使用客户端IP识别客户端
- 使用用户认证的方式识别用户,比如登陆
- Fat URLs,在URL中加入识别信息
- Cookie,能持久保存的识别标志
###HTTP Headers
下面表格中的七个http头部属性,经常用于携带用户信息,我们先介绍前面三个,后面四个在下一小节再仔细介绍

“From”一般包含用户电子邮箱,这可以用于鉴别用户身份。为了预防用户收到垃圾邮件,很少浏览器会在头部发出“From”。
“User-Agent”一般是告诉服务器浏览器的版本,以及操作系统的信息。这能使服务器有针对性地返回内容,有利于客户端渲染效果。但是这起不到识别用户身份的作用。以下是Netscape Navigator和IE的“User-Agent”
Navigator 6.2 User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.0; en-US; rv:0.9.4) Gecko/20011128 Netscape6/6.2.1 Internet Explorer 6.01 User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)
“Referer”包含用户从哪个页面跳转过来的。它一般不能用户识别用户身份,但是能记录用户个人偏好。
从上面的讨论可知, From, User-Agent, 和 Referer headers都无法用于识别用户身份,下面讨论能更精确识别用户身份的方式。
###Client IP Address
如果用户的IP不改变,那么通过IP也是识别用户的一种方式。即时HTTP头部没有携带IP地址,也可以通过TCP连接获取连接另一端的IP地址。但是通过IP地址识别用户存在以下缺点:
-
IP只能代表用户使用的机器,不能代表用户,一个用户可能使用多个电脑。或者一个电脑被多个用户使用。
-
很多网络提供商为用户提供的是动态IP地址,随时会变化
-
另一种情况就是NAT共享IP
-
HTTP代理和网关使得服务器看到的IP是代理或者网关的IP,而不是客户端的IP。虽然代理可以加上“Client-ip”和“X-forwarded-for”拓展头部—–它们的值为客户端真正的地址。但是很多代理不支持这种拓展头部。
依然有部分情况使用IP地址做用户识别,比如局域网内限制某些IP地址的电话访问某些保密资源。在因特网上则不能采取这种策略了,IP地址很容易被伪造。
###User Login
与其被动地凭借IP地址猜测用户的身份,服务器不如直接让用户使用账号密码认证登陆。从而验证其身份。
为了方便,HTTP自带内建的WWW-Authenticate 和 Authorization两个头部,它们可以携带用户信息发往服务器,一旦验证登陆通过,则以后每次请求都带上这个登陆信息。
如果服务器希望用户在访问网页之前登陆,则服务器可以返回一个401的要求登陆的信息给浏览器,然后浏览器会弹出一个登陆窗口,下次请求时就将带上这个登陆信息。如下图:
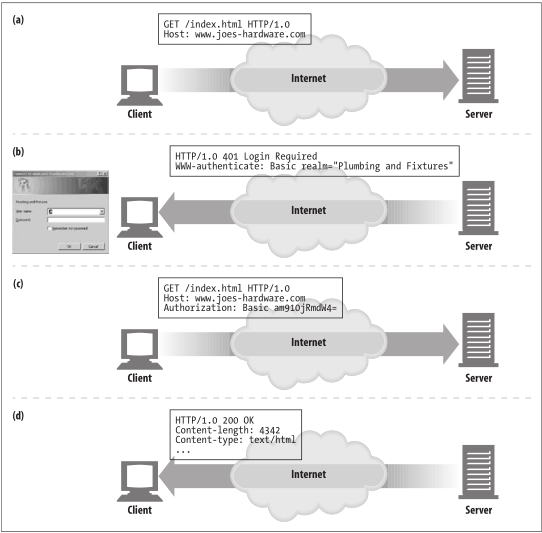
如上图,
-
用户访问 www.joes-hardware.com
-
网站并不知道用户身份,服务器返回一个401的登陆要求和WWW-Authenticate头部给客户端,然后浏览器就会弹出扥股窗口。
-
当用户输入账号密码,浏览器重复上一次请求,并且在头部加上Authorization信息指定账号密码,当然账号密码是加密的。
-
服务器可以识别客户端
-
以后浏览器的每次请求如果需要认证,都会自动带上刚才输入的账号密码。
然而,使用登陆认证的方式也不大方便,因为用户浏览每个网站都需要输入账号密码,太麻烦。
###Fat URLs
Fat URLs的原理就是在URL的前缀或者后缀加入用户信息,以此识别用户身份。但是它有诸多缺点。
-
URL太丑陋,是用户混淆。
-
URL不能共享,不能发给别人,因为URL中包含特定的用户和会话信息。
-
需要重写HTML页面,将其中的URL改为对应的fat URLs
-
如果不小心fat URLs中丢失了用户信息,会话将失效。
-
不能持久保存
###Cookies
Cookie是现在最好的识别用户、保存持久会话的最佳方案。Cookie没有以上几种方法的缺点,但是有时会结合以上几种方法一起使用,Cookie最开始是由Netscape开发的,现在已经被大部分浏览器支持。
Cookie使得HTTP头部需要重新定义,而且影响了缓存。另外很多浏览器禁止缓存cookie的内容。
Types of Cookes
session cookies和持久cookies,这就是常见的两种cookie。前者不是持久的,后者是持久的,会保存到本地。如果设置了Discard参数或者没有设置Expires和Max-Age参数,则代表是session cookies。
##How Cookies Work
用户首次访问网站时,网站并不知道用户身份,这时服务器生成一个标志用户的ID号,使用Set-Cookie 或者 Set-Cookie2携带这个ID返回给客户端,客户端保存这个cooked值,下次访问网站时,自动在头部携带上这个cookie。另外,cookie不止可以携带ID,还可以携带电话号码,邮箱地址等等信息。
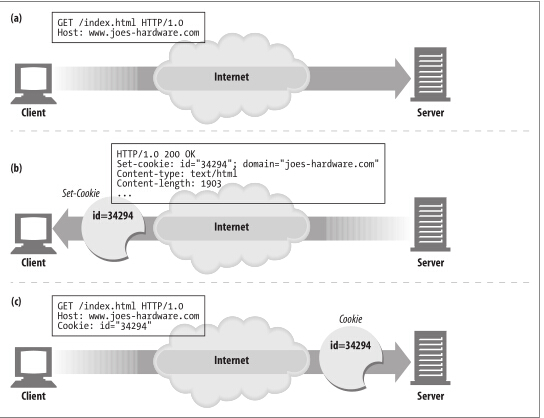
##Cookie Jar: Client-Side State
Cookie机制的全称为HTTP状态管理机制。
##Different Cookies for Different Sites
浏览器的cookie并不会全部发给某个服务器,这样会让网络传输变大,而且不是所有cookie都能被特定的网站识别,甚至会引起安全问题。
而且服务器返回Set-cookie回来给客户端时,可以通过制定domain和path,告诉客户端,这些cookie下次要发到哪个domain下的哪个path。
Cookie Ingredients (成分)
现在有两种Version 0 cookies(有时称为 “Netscape cookies”), 和 Version 1 (“RFC 2965”) cookies.它们都没被写入HTTP/1.1 规范。
前者就是我们现在经常使用的cookie,后者是拓展的,还没完全支持,普及。
Cookies and Session Tracking
容易理解
Cookies and Caching
简短的一段,但是缓存的概念不大理解,留作下次。
Cookies, Security, and Privacy
Cookie存在安全风险,而且很多网站滥用Set-cookie,甚至第三方营销公司会结合IP地址和Referer header记录用户的浏览习惯。但是作用还是大于风险的。